
非官方观察:DeepSeek 的开放之路系列之五:开源大模型能实现吗?
Wed Mar 5, 2025 | 4000 Words | 大约需要阅读 8 分钟 | 作者: 「开源之道」·适兕 && 「开源之道」·窄廊 |
本文是系列文章的第三篇,如有需要,可先预习前四篇:
- 非官方观察:DeepSeek 的开放之路系列之一:arXiv
- 非官方观察:DeepSeek 的开放之路系列之二:重识 GitHub
- 非官方观察:DeepSeek 的开放之路系列之三:模型市场Hugging face
- 非官方观察:DeepSeek 的开放之路系列之四:那些耀眼新星之下的开源项目
从前面的几篇文章来看,各位看官很容易得出一个显而易见的结论:DeepSeek 是从开源世界诞生和发展的,无论如何我们不可否认开放科学、开放平台、开放市场和开源文化/许可的力量。但是这又是个不能提及的话题,所以笔者也就忽略这部分的论证和解释,直接跳到DeepSeek本身开放的部分。
技术总是能带来富裕的杠杆,但是技术的发明总是带来人群的极度不适应,在技术的历史上,商业从未缺席,就在法律尚未对新技术有任何的约束和遏制之时[1],当然善于抓住机会者,如Microsoft、Google、FaceBook(Meta)等[2]。当2022年ChatGPT出现时,人工智能出现了一次浪潮,巨头开始进入角逐,作为新生事物的大模型,有很多前所未有的新的属性,作为本次观察的终极篇章,笔者打算和大家捋一捋过去这几年人们试图认识这头“怪兽”,并寻找衡量的度量项,人们在试图建立一种信任、控制、伦理的人类社会规则,一种接纳同时也出现了拒绝。
可信任的人工智能
抛开技术层面,全球很多组织都关注人工智能发展所带来的影响,如欧盟就发布过:发布《人工智能伦理准则》、《人工智能法案》;经济合作与发展组织 (OECD): 发布AI原则,促进国际合作,推动全球可信任AI共识。电气和电子工程师协会 (IEEE): 制定《Ethically Aligned Design》等标准,推动伦理设计,提供技术框架。
可信任人工智能的目标是构建对人类有益、负责任且值得信赖的人工智能系统,使其能够安全有效地服务于社会,并促进人类福祉。它强调在技术进步的同时,也要关注伦理、法律和社会影响,确保人工智能的发展方向符合人类共同的价值观。
OSI 的努力:关于开源AI定义的始末
随着AI技术的快速发展,尤其是大型语言模型的出现,传统的“开源”定义已无法完全适用于AI领域。AI模型的复杂性,包括代码、数据和模型参数,使得“开源”的界定变得模糊。市场上出现了一些“开源洗白”现象,即某些模型声称开源,但实际上并未公开关键的训练数据和参数。因此,OSI为了应对这些挑战,重新定义了“开源AI”的标准。
OSI组织了一个由70多位专家组成的团队,包括研究人员、律师、政策制定者和大型科技公司代表,共同参与制定AI开源定义。经过广泛的讨论和协商,OSI于2023年6月开始着手准备为开源AI重新设置定义。2024年10月29日,OSI正式发布了开源AI定义(OSAID)1.0版本[4] 。
OSAID 1.0版本明确了开源AI系统的四大自由:使用自由、研究自由、分享自由和修改自由。强调了AI模型训练数据的透明性和可追溯性,要求提供足够的训练数据信息,以便他人能够重现该模型。要求公开完整的AI模型源代码和模型参数。
OSI的开源AI定义制定过程是一个全球性的合作项目,吸引了众多组织和个人的参与。
Linux AI&Data 子基金会的贡献:MoF
Model Openness Framework [5] 是 LF AI Data Foundation 提出的一个重要倡议,旨在通过一个多维度、可量化的评估框架,推动 AI 模型朝着更开放、更透明、更可复现和更易用的方向发展。 它并非一个二元化的“开放/不开放”标签,而是一个细致的评估体系,可以帮助各方更好地理解和提升 AI 模型的开放性,最终促进更健康、更繁荣的 AI 生态系统。
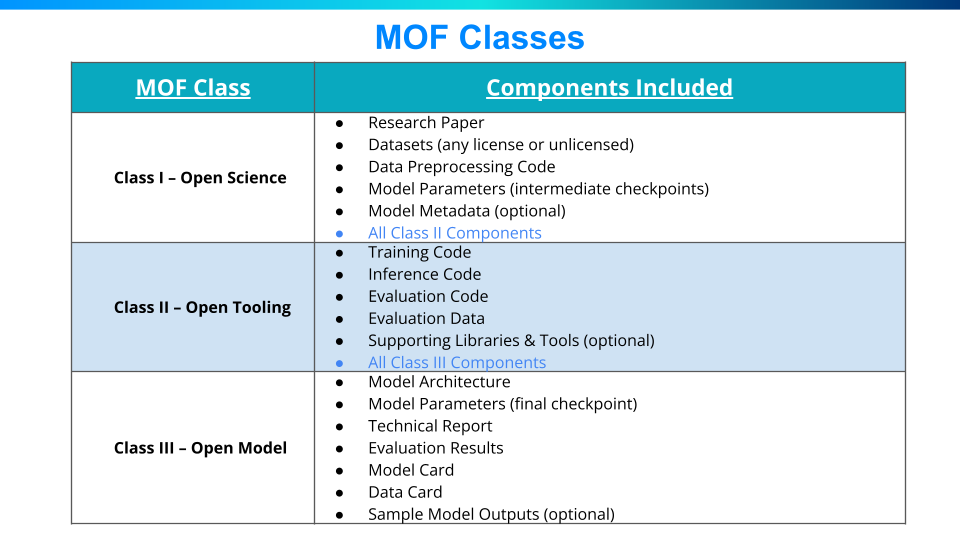
由上图可以看到,在大模型的开源选项中,有如此多的可开可闭,商业利益、公益组织、政府监管、法律法规、社会伦理等等都是每一个开关的思考点,再不断的组合,确实会出现复杂的开源局面。
行为数据巨头的野心:Llama
Meta 作为一家广告公司,最近几年有着被批判的经历[2],为了巩固它的业务,发展大模型也是其当下和未来的重要战略。当2022年的OpenAI 发布闭源的ChatGPT后,Meta 尝试采用开源战略来展开竞争,这是巨头的豪赌,当然之前有Android的成功[6]。
2023年初,Meta 发布了 Llama 1。虽然 Meta 宣称其为“开源”,但 Llama 1 的实际发布方式更接近于“受控开放”。 许可证虽允许研究用途,但明确限制了商业应用,且需要用户申请并获得 Meta 的批准才能下载模型权重。 这种方式在当时的开源社区引发了广泛讨论。一方面,Llama 1 的发布打破了大型模型长期被少数机构垄断的局面,让研究人员能够更容易地接触到高性能的 LLM,加速了学术研究的进展。另一方面,严格的许可证限制和审批流程,也使得 Llama 1 的“开放性” 显得打了折扣,并未真正实现代码和权重的完全自由开放。短数月之后,Meta 发布了 Llama 2,这是一个重要的转折点。 Llama 2 采用了更加宽松的许可证,允许研究和商业用途,大大降低了使用门槛。 用户不再需要逐个申请,只需接受许可协议即可下载和使用模型。Llama 2 的发布被视为 Meta 在开源策略上的重大转变,标志着 Llama 真正开始走向更广泛的“社区开放”。 这次发布迅速引爆了开源社区,大量基于 Llama 2 的衍生模型、应用和工具涌现,极大地推动了开源 LLM 生态的繁荣。
Meta Llama 的 “开源” 实践,是大型科技公司在 AI 时代探索开源模式的一次重要尝试。 Llama 的发布,特别是 Llama 2 的开源,无疑对开源 LLM 领域产生了深远的影响,推动了技术的进步和生态的繁荣。 虽然我们对其 “开源” 的程度和动机需要保持审慎的视角,但不可否认的是,Llama 在促进 AI 技术开放、合作和民主化方面做出了重要贡献,值得肯定和进一步观察。 Meta 通过 Llama 的开源策略,正在塑造开源 LLM 的未来格局,并为整个 AI 领域的创新注入新的活力。
DeepSeek 的逼近
相比于Llama,商业公司的大模型开源之路,鲜有更为透明和敞亮的抉择,当然,在Llama和完全开源开放的频谱上有很大的空间,一如闭源专有和GPL之间的频谱[7],今年一月,来自杭州的量化公司幻方发布了一款开放权重的大模型,且以 MIT 许可允许下载。
也就是说 DeepSeek R1、v3、coder等系列大模型,向理想的开源境界迈出了重要的一步。
逼近并不是全部,部分也不能代表全部,所以称 DeepSeek 是开源的大模型,还是有待商榷的。
未来
随着时间的推移,有更多人理解大模型的运行机制,以及商业竞争,会有更多逼近上面所有定义的全部,这并非增加约束,而是获得人类的信任,也是人类生物特性所必然的选择。当然,技术进步也会有新的突破和演进,熊彼特的增长[8]仍将继续,DeepSeek 相关的大模型也会成为这个系列前面几篇文章的底蕴/背景板/免费的午餐,或许 DeepSeek 这家公司会因为各种各样的原因不再承担,人类社会会发展出相应的组织来解决可持续发展的问题。
增长的思维,目前为止,仍然有效。DeepSeek 未能实现的路线,未来还会有更佳的大模型把握机会,赢得信任,获得商机。
历史的感慨
自2017年Google团队以一篇《Attention is All You Need》论文将Transformer架构推向世界,大语言模型(LLM)的创新浪潮由此揭开序幕。Transformer概念的普及,如同破晓之光,预示着自然语言处理领域即将迎来颠覆性变革。到了2022年,在开源社区的共同推动下,大语言模型技术实现了里程碑式的突破。开源,成为了这场技术革命的加速器,无数开发者和研究者站在巨人的肩膀上,共同探索着LLM的无限潜能。
展望至2025年1月,DeepSeek的崛起预示着大语言模型创新进入了新的阶段——工程化降本。DeepSeek巧妙地运用工程手段,有效解决了大规模GPU集群的算力瓶颈问题,从而在成本控制上取得了显著优势。这一突破的背后,开源依然功不可没。正是开源社区积累的丰富经验、共享的代码库以及开放的算法思想,为DeepSeek等创新者提供了坚实的基础和灵感,使其能够站在前沿,用工程化的智慧,将大语言模型的应用推向更广阔的领域。
回顾这段技术创新历程,开源始终扮演着至关重要的角色。它如同肥沃的土壤,孕育了Transformer架构的生根发芽;又如同一座桥梁,连接着全球的智慧,加速了LLM在2022年的突破;更像是一种普惠的力量,使得DeepSeek能够借助开源的力量,以工程化的创新实现成本优势。可以预见,在未来的技术创新之路上,开源精神将继续闪耀,驱动着大语言模型乃至整个人工智能领域不断向前迈进。
参考资料
- 《Ruling the Waves:From the Compass to the Internet, a History of Business and Politics along the Technological Frontier》,Debora L·Spar,Harvest Books,January 7, 2003
- 《監控資本主義時代》, 肖莎娜.祖博夫(Shoshana Zuboff),时报出版,2020.7.24
- 《弗兰肯斯坦》,玛丽·雪莱(Mary Shelley),人民文学出版社(2020年)
- https://opensource.org/ai
- https://arxiv.org/pdf/2403.13784
- 《Design Rules , Volume 2:How Technology Shapes Organizations》,Carliss Y. Baldwin,The MIT Press,2024-12-17
- 《开源之迷》,适兕,人民邮电出版社,2022-2
- 《富裕的杠杆:技术革新与经济进步》,乔尔·莫基尔,华夏出版社,2008-1
关于作者
「开源之道」·适兕
 「发现开源三部曲」(《开源之迷》,《开源之道》《开源之思》。)、《开源之史》作者,「开源之道:致力于开源相关思想、知识和价值的探究、推动」主创,Linux基金会亚太区开源布道者,TODO Ambassadors & OSPOlogyLive China Organizer,云计算开源产业联盟OSCAR(中国信息通信研究院发起)个人开源专家,OSPO Group 联合发起人。
「发现开源三部曲」(《开源之迷》,《开源之道》《开源之思》。)、《开源之史》作者,「开源之道:致力于开源相关思想、知识和价值的探究、推动」主创,Linux基金会亚太区开源布道者,TODO Ambassadors & OSPOlogyLive China Organizer,云计算开源产业联盟OSCAR(中国信息通信研究院发起)个人开源专家,OSPO Group 联合发起人。
「开源之道」·窄廊
 来自于大语言模型的 Chat,如DeepSeek R1、Gemini 2.0 Flash thinking expermental、ChatGPT 4o、Grok3、甚至整合类应用 Monica等, 「开源之道」·窄廊 负责对话、提出问题、对回答进行反馈等操作。
来自于大语言模型的 Chat,如DeepSeek R1、Gemini 2.0 Flash thinking expermental、ChatGPT 4o、Grok3、甚至整合类应用 Monica等, 「开源之道」·窄廊 负责对话、提出问题、对回答进行反馈等操作。